UT: Upstream request timeout in addition to 504 response code.
LR: Connection local reset in addition to 503 response code.
UR: Upstream remote reset in addition to 503 response code.
UC: Upstream connection termination in addition to 503 response code.
DI: The request processing was delayed for a period specified via fault injection.
FI: The request was aborted with a response code specified via fault injection.
RL: The request was ratelimited locally by the HTTP rate limit filterin addition to 429 response code.
UAEX: The request was denied by the external authorization service.
RLSE: The request was rejected because there was an error in rate limit service.
IH: The request was rejected because it set an invalid value for a strictly-checked headerin addition to 400 response code.
SI: Stream idle timeout in addition to 408 response code.
DPE: The downstream request had an HTTP protocol error.
UPE: The upstream response had an HTTP protocol error.
UMSDR: The upstream request reached max stream duration.
OM: Overload Manager terminated the request.
DF: The request was terminated due to DNS resolution failure.
10.2 데이터 플레인 문제 식별하기
들어가며: 데이터 플레인 디버깅부터 하지 말 것
일상적인 운영: 데이터 플레인 문제를 처리가 일반적
바로 데이터 플레인 디버깅에 착수할수도 있으나 컨트롤 플레인 문제를 추정 원인에서 빠르게 배제하는 것이 더욱 중요
컨트롤 플레인의 주요 기능이 데이터 플레인을 최신 설정으로 동기화하는 것임을 감안한다면?
첫 단계는 컨트롤 플레인과 데이터 플레인이 동기화된 상태인지 확인하는 것
데이터 플레인이 최신 상태인지 확인하는 방법 How to verify that the data plane is up to date
데이터 플레인 설정은 설계상 궁극적으로 일관성을 가짐
컨트롤 플레인과 동기화하기 전까지는 환경(서비스, 엔드포인트, 상태)이나 설정의 변화가 데이터 플레인에 즉시 반영 X
ex) 컨트롤 플레인에서 특정 서비스의 개별 엔드포인트 IP 주소를 데이터 플레인으로 보낼 때 (서비스 내의 각 파드 IP 주소와 대강 동일)
엔드포인트 중 어느 하나가 비정상이 되면, 쿠버네티스가 이를 인지하고 파드를 비정상으로 표시하는 데 시간 소요
컨트롤 플레인도 특정 시점에 문제를 인지하고 엔드포인트를 데이터 플레인에서 제거
위 과정을 통해 컨트롤 플레인은 최신 설정으로 돌아오며, 프록시 설정도 다시 일관된 상태 유지
아래) 데이터 플레인을 업데이트하기 위해 발생하는 이벤트를 시각화워크로드가 비정상이 된 후 데이터 플레인 구성 요소의 설정이 업데이트될 때까지 일련의 이벤트
kubelet은 주기적으로 Node 내에서 실행 중인 Pod의 상태를 확인
Kubernetes API서버는 상태 확인을 실패한 Pod를 통보 받음
API 서버가 모든 이해 당사자들에게 알림
istiod가 데이터 플레인을 업데이트해 설정에서 엔드포인트를 제거
건강하지 않은 인스턴스로는 더 이상 트래픽이 전송되지 않음
워크로드와 이벤트 개수가 늘어나는 대규모 클러스터에서는 데이터 플레인을 동기화하는 데 필요한 시간도 비례하여 증가
데이터 플레인이 최신 설정과 동기화했는지 확인 (istioctl proxy-status)
docker exec -it myk8s-control-plane istioctl proxy-status
NAME CLUSTER CDS LDS EDS RDS ECDS ISTIOD VERSION
catalog-6cf4b97d-l44zk.istioinaction Kubernetes SYNCED SYNCED SYNCED SYNCED NOT SENT istiod-8d74787f-ltkhs 1.17.8
catalog-v2-56c97f6db-d74kv.istioinaction Kubernetes SYNCED SYNCED SYNCED SYNCED NOT SENT istiod-8d74787f-ltkhs 1.17.8
catalog-v2-56c97f6db-m6pvj.istioinaction Kubernetes SYNCED SYNCED SYNCED SYNCED NOT SENT istiod-8d74787f-ltkhs 1.17.8
istio-egressgateway-85df6b84b7-2f4th.istio-system Kubernetes SYNCED SYNCED SYNCED NOT SENT NOT SENT istiod-8d74787f-ltkhs 1.17.8
istio-ingressgateway-6bb8fb6549-hcdnc.istio-system Kubernetes SYNCED SYNCED SYNCED SYNCED NOT SENT istiod-8d74787f-ltkhs 1.17.8
istioctl proxy-status 로 데이터 플레인의 동기화 여부 확인
SYNCED: istiod가 보낸 마지막 설정을 Envoy가 확인함
NOT SENT: istiod가 아무것도 Envoy로 보내지 않음 (보통은 istiod가 보낼 것이 없기 때문)
STALE: istiod가 Envoy에 업데이트를 보냈지만 확인받지 못함
원인
istiod가 과부하
Envoy와 istiod 사이의 커넥션 부족 또는 끊김
Istio 버그
위 실습을 통해 확인한 사항
proxy-status 확인 시 설정을 받지 못한 stale 상태의 워크로드 없음
확인해야 할 사항
컨트롤 플레인에 문제가 있을 가능성은 낮으므로 데이터 플레인 구성 요소를 조사해야 함
데이터 플레인 구성 요소에서 가장 일반적인 문제는 잘못된 워크로드 설정.
Kiali를 사용하면 빠르게 설정 검증 가능
키알리로 잘못된 설정 발견하기 Discovering misconfigurations with Kiali
잘못된 설정 발견
대시보드 Overview 확인
istioinaction 네임스페이스에 경고 표시
경고 아이콘 클릭 → 내장 편집기에서 경고 메시지 확인 - DocsㅇㅅㅇKIA1107 - Subset not found 경고 아이콘 위로 마우스를 올리면 경고 메시지 ‘KIA1107 Subnet not found’ 확인 가능 (Kiali 공식 문서 참고 -Docs)
KIA1107 경고의 해결책: 존재하지 않은 부분집합을 가리키는 루트 수정 필요
부분집합 이름의 오타를 수정해야 할 수 있음
DestinationRule 에서 빠트린 부분집합이 있을 수 있음
Kiali 검증은 이슈 파악이 손쉬워 워크로드가 예상대로 동작하지 않을 때 취하는 첫 조치 중 하나
istioctl로 잘못된 설정 발견하기 Discovering misconfigurations with istioctl
istio 명령어 중 오설정된 워크로드 트러블슈팅에 유용한 2가지 명령어
istio analyze
istio describe
istioctl 로 Istio 설정 분석하기ANALYZING ISTIO CONFIGURATIONS WITH ISTIOCTL
istioctl analyze
Istio 설정을 분석하는 강력한 진단 도구
이미 문제가 발생한 클러스터에 실행하여 검사 가능
리소스를 잘못 구성하는 것을 방지하고자 클러스터에 적용하기 전에 설정이 유효한지 검사 가능
여러 분석기를 실행할 수 있음 - 각 분석기는 특정 문제를 감지하는 데 특화됨
쉬운 확장성
istioctl analyze로 감지된 문제 살펴보기
# analyze help docs 확인
docker exec -it myk8s-control-plane istioctl analyze -h
# 진단 가능한 analyzer 목록 보기
docker exec -it myk8s-control-plane istioctl analyze --list-analyzers
...
# istioctl analyze 명령어로 istioinaction 네임스페이스 문제 진단
docker exec -it myk8s-control-plane istioctl analyze -n istioinaction
Error [IST0101] (VirtualService istioinaction/catalog-v1-v2) Referenced host+subset in destinationrule not found: "catalog.istioinaction.svc.cluster.local+version-v1"
Error [IST0101] (VirtualService istioinaction/catalog-v1-v2) Referenced host+subset in destinationrule not found: "catalog.istioinaction.svc.cluster.local+version-v2"
Error: Analyzers found issues when analyzing namespace: istioinaction.
See https://istio.io/v1.17/docs/reference/config/analysis for more information about causes and resolutions.
# 이전 명령어 종료 코드 확인
echo $? # (참고) 0 성공
79
진단 가능한 analyzer 목록 보기istioctl analyze 명령어로 istioinaction 네임스페이스 문제 진단
IST0101에러가 확인됨
Istio 리소스(VirtualService)가 참조하는 다른 리소스(DestinationRule의 서브셋)가 존재하지 않음을 확인할 수 있음
워크로드별로 설정 오류 찾기 DETECTING WORKLOAD-SPECIFIC MISCONFIGURATIONS
istioctl describe
워크로드별 설정을 기술하는데 사용
istio 설정(워크로드 하나에 직간접적으로 영향)을 분석해 요약 내용을 출력
요약 내용은 다음 질문에 답변을 제공 (워크로드 관련)
이 워크로드는 서비스 메시의 일부인가?
어떤 VirtualService 와 DestinationRule 이 적용되는가?
상호 인증 트래픽을 요구하는가?
istioctl describe 로 설정 오류 확인
# catalog pod 이름 변수화
kubectl get pod -n istioinaction -l app=catalog -o jsonpath='{.items[0].metadata.name}'
CATALOG_POD1=$(kubectl get pod -n istioinaction -l app=catalog -o jsonpath='{.items[0].metadata.name}')
# catalog pod istioctl experimental describe로 확인
# 단축키 : experimental(x), describe(des)
docker exec -it myk8s-control-plane istioctl experimental describe -h
docker exec -it myk8s-control-plane istioctl x des pod -n istioinaction $CATALOG_POD1
Pod: catalog-6cf4b97d-l44zk
Pod Revision: default
Pod Ports: 3000 (catalog), 15090 (istio-proxy)
--------------------
Service: catalog
Port: http 80/HTTP targets pod port 3000
--------------------
Effective PeerAuthentication:
Workload mTLS mode: PERMISSIVE
Exposed on Ingress Gateway http://172.18.0.2
VirtualService: catalog-v1-v2
WARNING: No destinations match pod subsets (checked 1 HTTP routes)
Warning: Route to subset version-v1 but NO DESTINATION RULE defining subsets!
Warning: Route to subset version-v2 but NO DESTINATION RULE defining subsets!
# 문제 해결(destinationrule 적용) 후 확인
cat ch10/catalog-destinationrule-v1-v2.yaml
kubectl apply -f ch10/catalog-destinationrule-v1-v2.yaml
docker exec -it myk8s-control-plane istioctl x des pod -n istioinaction $CATALOG_POD1
Pod: catalog-6cf4b97d-l44zk
Pod Revision: default
Pod Ports: 3000 (catalog), 15090 (istio-proxy)
--------------------
Service: catalog
Port: http 80/HTTP targets pod port 3000
DestinationRule: catalog for "catalog.istioinaction.svc.cluster.local"
Matching subsets: version-v1 # 일치하는 부분집합
(Non-matching subsets version-v2) # 일치하지 않은 부분집합
No Traffic Policy
--------------------
Effective PeerAuthentication:
Workload mTLS mode: PERMISSIVE
Exposed on Ingress Gateway http://172.18.0.2
VirtualService: catalog-v1-v2 # 이 파드로 트래픽을 라우팅하는 VirtualService
Weight 20%
# 다음 점검 방법을 위해 오류 상황으로 원복
kubectl delete -f ch10/catalog-destinationrule-v1-v2.yaml
istioctl x des pod -n istioinaction $CATALOG_POD1 로 문제 해결(destinationrule 적용) 후 확인 Matching subsets: version-v1 - 일치하는 부분집합 (Non-matching subsets version-v2) - 일치하지 않은 부분집합
# 로컬 YAML 파일 검증
istioctl analyze --use-kube=false samples/bookinfo/networking/bookinfo-gateway.yaml
# 라이브 클러스터와 YAML 파일 조합 검증
istioctl analyze samples/bookinfo/networking/bookinfo-gateway.yaml samples/bookinfo/networking/destination-rule-all.yaml
# 특정 경고 억제
istioctl analyze --namespace default --suppress "IST0102=Namespace default"
# 모든 네임스페이스 분석
istioctl analyze --all-namespaces
# 디렉토리 내 모든 YAML 파일 분석
istioctl analyze --recursive my-istio-config/
GitHub Actions
name: Istio YAML 분석
on:
push:
paths:
- 'istio-configs/**.yaml'
pull_request:
jobs:
istio-analyze:
runs-on: ubuntu-latest
steps:
- name: Checkout repository
uses: actions/checkout@v3
- name: Install istioctl
run: |
curl -L https://istio.io/downloadIstio | ISTIO_VERSION=1.22.0 sh -
export PATH="$PATH:./istio-1.22.0/bin"
echo "PATH=$PATH:./istio-1.22.0/bin" >> $GITHUB_ENV
- name: Run istioctl analyze
run: |
# --use-kube=false를 지정하면 클러스터 없이도 로컬 파일만으로 분석 가능
istioctl analyze ./istio-configs --use-kube=false --output json > analyze-report.json || true
cat analyze-report.json
- name: Fail if issues found
run: |
if grep -q '"Level":"Error"' analyze-report.json; then
echo "Istio analyze found errors"
exit 1
fi
name: Istio YAML Validation
on:
pull_request:
branches:
- main
jobs:
validate-istio:
runs-on: ubuntu-latest
steps:
# 리포지토리 체크아웃
- name: Checkout code
uses: actions/checkout@v3
# Istio 설치
- name: Install istioctl
run: |
curl -L https://istio.io/downloadIstio | ISTIO_VERSION=1.25.2 sh -
mv istio-1.25.2/bin/istioctl /usr/local/bin/
istioctl version
# YAML 파일 검증
- name: Run istioctl analyze
run: |
istioctl analyze --use-kube=false ./istio-config/*.yaml
continue-on-error: false
# 클러스터 접근 설정 (필요한 경우)
- name: Setup kubeconfig
run: |
echo "${{ secrets.KUBECONFIG }}" > kubeconfig
export KUBECONFIG=kubeconfig
# 라이브 클러스터 분석
- name: Run istioctl analyze with cluster
run: |
istioctl analyze ./istio-config/bookinfo-gateway.yaml
# 파드 구성 확인 (배포 후)
- name: Run istioctl describe
run: |
POD_NAME=$(kubectl get pods -l app=ratings -o jsonpath='{.items[0].metadata.name}')
istioctl describe pod $POD_NAME
과정 중 istioctl describe 사용 (디버깅용으로 로그 출력)
...
- name: Describe Istio service
run: |
istioctl x describe svc reviews.default.svc.cluster.local || true
GitLab CI
# .gitlab-ci.yml
stages:
- lint
- build
- deploy
variables:
ISTIO_VERSION: "1.20.0" # 사용하는 Istio 버전에 맞게 조정
istioctl_analyze:
stage: lint
image:
name: gcr.io/google.com/cloudsdk/cloud-sdk:latest # kubectl, istioctl이 포함된 이미지 사용 (또는 커스텀 이미지)
entrypoint: [""] # Entrypoint를 재정의하여 쉘 스크립트 실행
before_script:
# istioctl 다운로드 및 설치 (만약 이미지에 포함되어 있지 않다면)
- apt-get update && apt-get install -y curl
- curl -L https://istio.io/downloadIstio | ISTIO_VERSION=$ISTIO_VERSION sh -
- export PATH=$PWD/istio-$ISTIO_VERSION/bin:$PATH
script:
- echo "Analyzing Istio YAML files..."
# 모든 Istio 관련 YAML 파일이 있는 디렉토리를 지정
# 여기서는 project/istio-config/ 아래에 모든 Istio 설정 파일이 있다고 가정
- istioctl analyze project/istio-config/
# 또는 특정 파일만 지정
# - istioctl analyze project/istio-config/gateway.yaml project/istio-config/virtualservice.yaml
- if [ $? -ne 0 ]; then
echo "Istio configuration analysis failed. Please check the reported errors."
exit 1
fi
- echo "Istio configuration analysis passed."
only:
- merge_requests # PR/MR 시에만 실행
- main # main 브랜치 커밋 시에도 실행
들어가며: 데이터 플레인의 잘못된 설정, 혹은 문제 파악 후에도 이슈 해소가 되지 않았을 경우
Envoy 설정 전체에 대해 수동 조사 필요
Envoy 관리(admin) 인터페이스 Envoy administration interface
프록시의 특정 부분(로그 수준 증가 등)을 수정하는 기능 수행
Envoy 설정을 노출함
모든 서비스 프록시에서 포트 15000으로 접근 가능
# Envoy 관리 인터페이스 포트포워딩 (15000)
kubectl port-forward deploy/catalog -n istioinaction 15000:15000
open http://localhost:15000
# 현재 적재한 엔보이 설정 출력 : 데이터양이 많다!
curl -s localhost:15000/config_dump | wc -l
13952
admin 페이지config_dump (총 13952 라인)
Envoy configuration은 사람을 위한 것이 아니라 기계를 위한 것 (출력이 너무 커서 기본적으로 사람이 읽을 수 없음)
서비스 이름을 통해 Ingress Gateway에서 클러스터의 엔드포인트를 수동으로 쿼리 가능 (istioctl proxy-config endpoints 명령어)
# 엔드포인트 정보 확인 : IP 정보
docker exec -it myk8s-control-plane istioctl proxy-config endpoints deploy/istio-ingressgateway -n istio-system \
--cluster "outbound|80|version-v1|catalog.istioinaction.svc.cluster.local"
ENDPOINT STATUS OUTLIER CHECK CLUSTER
10.10.0.12:3000 HEALTHY OK outbound|80|version-v1|catalog.istioinaction.svc.cluster.local
# 해당 IP 쿼리로 실제 워크로드가 있는지 확인
kubectl get pod -n istioinaction --field-selector status.podIP=10.10.0.12 -owide --show-labels
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
catalog-6cf4b97d-l44zk 2/2 Running 0 5h58m 10.10.0.12 myk8s-control-plane <none> <none>
status.podIP가 10.10.0.12 인 워크로드 존재
엔드포인트 정보에서 확인된 IP로 실제 워크로드가 확인 되었음
트래픽을 워크로드로 라우팅하도록 서비스 프록시를 설정하는 Envoy API 리소스 체인 전체가 완성됨
애플리케이션 문제 트러블슈팅하기 Troubleshooting application issues
마이크로서비스 기반 애플리케이션에서 서비스 프록시가 생성하는 로그와 메트릭의 이점
이슈 트러블슈팅에 도움이 됨
성능 병목을 일으키는 서비스 디스커버리
빈번하게 실패하는 엔드포인트 식별
성능 저하 감지
Envoy 액세스 로그와 메트릭을 사용해, 이 문제들 중 일부를 트러블슈팅 (트러블슈팅 임의 발생 시키기)
간헐적으로 제한 시간을 초과하는 느린 워크로드 준비하기 SETTING UP AN INTERMITTENTLY SLOW WORKLOAD THAT TIMES OUT
설정 전 정상 통신 환경 상태 확인
# 신규 터미널
for in in {1..9999}; do curl http://catalog.istioinaction.io:30000/items -w "\nStatus Code %{http_code}\n"; sleep 1; done
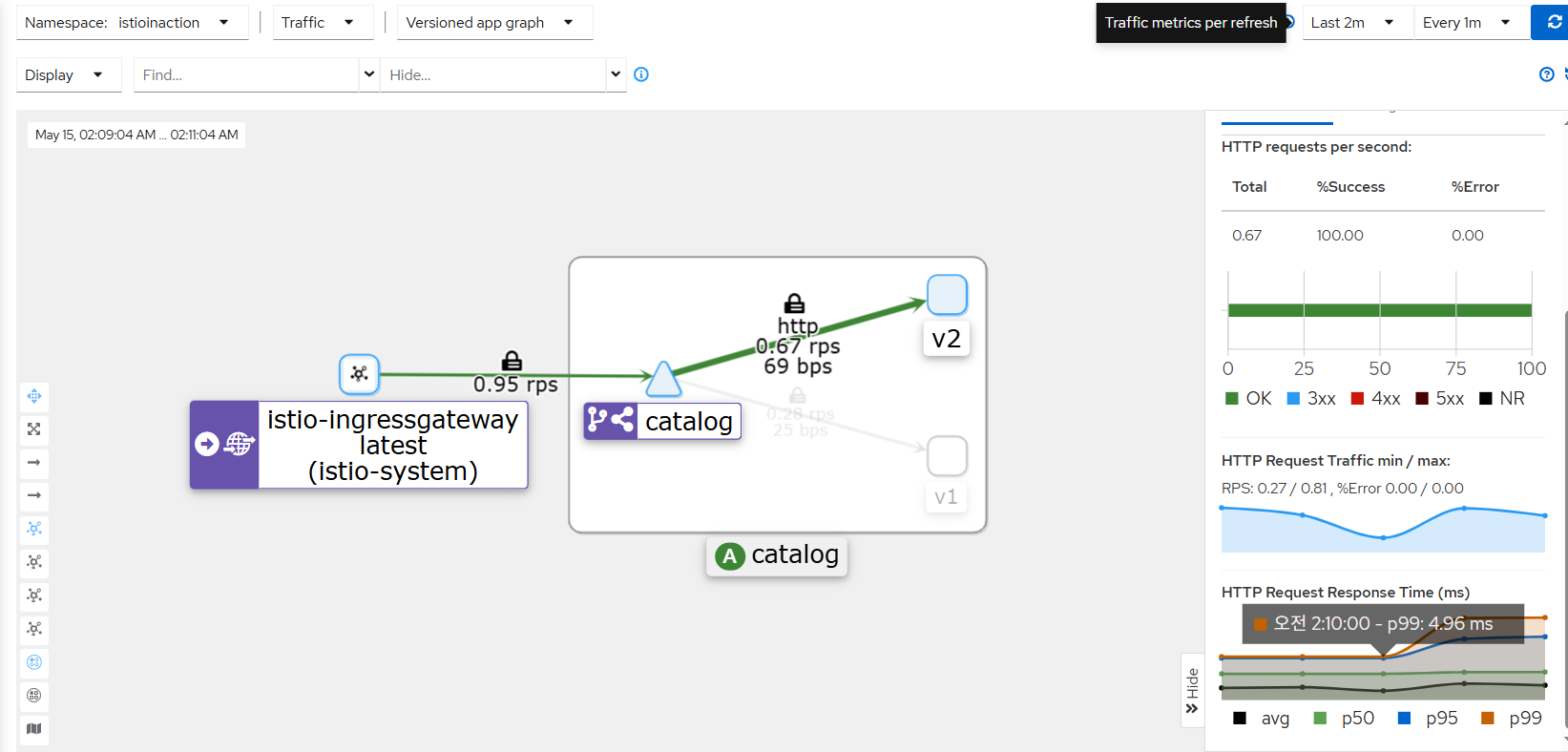
kiali: catalog - 100% 성공
kiali : catalog 에 v2 링크 클릭 후 오른쪽 탭 메뉴 하단에 HTTP Request Response Time(ms)에 p99 확인 → 4.96ms
Grafana - Istio Mesh 대시보드
catalog 워크로드가 간헐적으로 응답을 느리게 반환하도록 설정
# catalog v2 파드 중 첫 번째 파드 이름 변수 지정
CATALOG_POD=$(kubectl get pods -l version=v2 -n istioinaction -o jsonpath={.items..metadata.name} | cut -d ' ' -f1)
echo $CATALOG_POD
catalog-v2-56c97f6db-d74kv
# 해당 파드에 latency (지연) 발생하도록 설정
kubectl -n istioinaction exec -c catalog $CATALOG_POD \
-- curl -s -X POST -H "Content-Type: application/json" \
-d '{"active": true, "type": "latency", "volatile": true}' \
localhost:3000/blowup ;
blowups=[object Object]
# 신규 터미널
for in in {1..9999}; do curl http://catalog.istioinaction.io:30000/items -w "\nStatus Code %{http_code}\n"; sleep 1; done
응답 지연 설정
Grafana - Istio Mesh 대시보드 : v2 에 P90, P99 레이턴스 확인 , v1 과 비교 v2 레이턴시 p90: 800 ms, p99: 980 ms
kiali: catalog v2p99: 960 ms
Istio 에 요청 처리 제한 시간 0.5초가 되도록 VirtualService 설정2가지 변경 사항 : catalog v2 중 파드 1대는 간헐적으로 느린 응답을 하고, istio-proxy 가 요청 0.5초 이상 시 시간 초과 발생
# VirtualService 확인 (istioinaction)
kubectl get vs -n istioinaction
NAME GATEWAYS HOSTS AGE
catalog-v1-v2 ["catalog-gateway"] ["catalog.istioinaction.io"] 6h44m
# 타임아웃(0.5s) 적용
kubectl patch vs catalog-v1-v2 -n istioinaction --type json \
-p '[{"op": "add", "path": "/spec/http/0/timeout", "value": "0.5s"}]'
# 적용확인
kubectl get vs catalog-v1-v2 -n istioinaction -o jsonpath='{.spec.http[?(@.timeout=="0.5s")]}' | jq
...
"timeout": "0.5s"
}
# 신규 터미널
for in in {1..9999}; do curl http://catalog.istioinaction.io:30000/items -w "\nStatus Code %{http_code}\n"; sleep 1; done
upstream request timeout
Status Code 504
upstream request timeout
Status Code 504
..
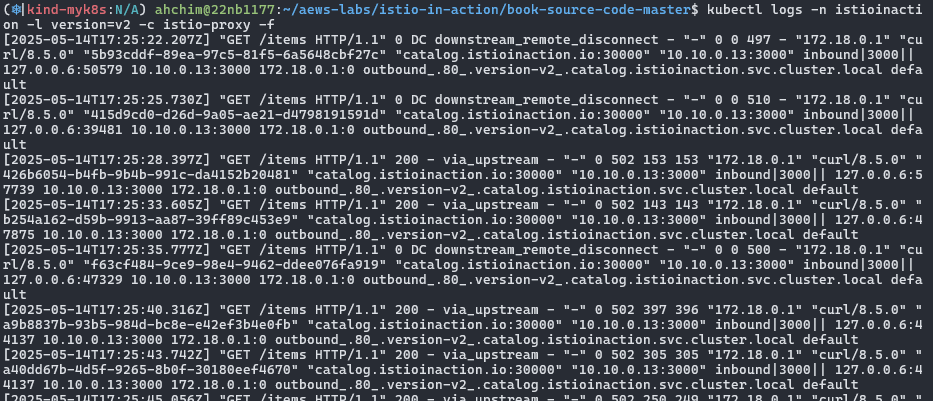
# ingressgateway 로그 확인
kubectl logs -n istio-system -l app=istio-ingressgateway -f
[2025-05-09T08:45:41.636Z] "GET /items HTTP/1.1" 504 UT response_timeout - "-" 0 24 501 - "172.18.0.1" "curl/8.7.1" "cb846eff-07ac-902e-9890-7af478c84166" "catalog.istioinaction.io:30000" "10.10.0.13:3000" outbound|80|version-v2|catalog.istioinaction.svc.cluster.local 10.10.0.7:58078 10.10.0.7:8080 172.18.0.1:61108 - -
[2025-05-09T08:45:43.175Z] "GET /items HTTP/1.1" 200 - via_upstream - "-" 0 502 375 374 "172.18.0.1" "curl/8.7.1" "3f2de0c1-5af2-9a33-a6ac-bca08c1ee271" "catalog.istioinaction.io:30000" "10.10.0.13:3000" outbound|80|version-v2|catalog.istioinaction.svc.cluster.local 10.10.0.7:58084 10.10.0.7:8080 172.18.0.1:61118 - -
...
kubectl logs -n istio-system -l app=istio-ingressgateway -f | grep 504
...
# label이 version=v2인 proxy 로그 확인
kubectl logs -n istioinaction -l version=v2 -c istio-proxy -f
[2025-05-09T08:42:38.152Z] "GET /items HTTP/1.1" 0 DC downstream_remote_disconnect - "-" 0 0 500 - "172.18.0.1" "curl/8.7.1" "69fef43c-2fea-9e51-b33d-a0375b382d86" "catalog.istioinaction.io:30000" "10.10.0.13:3000" inbound|3000|| 127.0.0.6:36535 10.10.0.13:3000 172.18.0.1:0 outbound_.80_.version-v2_.catalog.istioinaction.svc.cluster.local default
...
타임아웃(0.5s) 적용 및 확인 오류 확인504 발생 확인 - 전체 ingress gateway 로그 중 504 발생 확인 - v2
kiali : catalog v2
Grafana - Istio Mesh 대시보드 : 500 응답 증가, v2 에 Success Rate 75% 확인
엔보이 액세스 로그 이해하기 + 엔보이 액세스 로그 형식 바꾸기
Istio는 프록시가 로그를 TEXT 형식으로 기록하도록 기본 설정 (간결하지만, 읽기는 어려움)
JSON 형식을 사용하게 설정: 값이 키와 연결돼 의미를 알 수 있음
# 형식 설정 전 로그 확인
kubectl logs -n istio-system -l app=istio-ingressgateway -f | grep 504
...
# MeshConfig 설정 수정
kubectl edit -n istio-system cm istio
...
mesh: |-
accessLogFile: /dev/stdout # 기존 설정되어 있음
accessLogEncoding: JSON # 추가
...
# 형식 설정 후 로그 확인
kubectl logs -n istio-system -l app=istio-ingressgateway -f | jq
...
{
"upstream_host": "10.10.0.13:3000", # 요청을 받는 업스트림 호스트
"bytes_received": 0,
"upstream_service_time": null,
"response_code_details": "response_timeout",
"upstream_cluster": "outbound|80|version-v2|catalog.istioinaction.svc.cluster.local",
"duration": 501, # 500ms 인 제한 시간 초과
"response_code": 504,
"path": "/items",
"protocol": "HTTP/1.1",
"upstream_transport_failure_reason": null,
"connection_termination_details": null,
"method": "GET",
"requested_server_name": null,
"start_time": "2025-05-09T08:56:38.988Z",
"downstream_remote_address": "172.18.0.1:59052",
"upstream_local_address": "10.10.0.7:57154",
"downstream_local_address": "10.10.0.7:8080",
"bytes_sent": 24,
"authority": "catalog.istioinaction.io:30000",
"x_forwarded_for": "172.18.0.1",
"request_id": "062ad02a-ff36-9dcc-8a7d-68eabb01bbb5",
"route_name": null,
"response_flags": "UT", # 엔보이 응답 플래그, UT(Upstream request Timeout)로 중단됨, '업스트림 요청 제한 시간 초과'
"user_agent": "curl/8.7.1"
}
...
# slow 동작되는 파드 IP로 느린 동작 파드 확인!
CATALOG_POD=$(kubectl get pods -l version=v2 -n istioinaction -o jsonpath={.items..metadata.name} | cut -d ' ' -f1)
kubectl get pod -n istioinaction $CATALOG_POD -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
catalog-v2-56c97f6db-d74kv 2/2 Running 0 7h11m 10.10.0.13 myk8s-control-plane <none> <none>
기존 로그 확인JSON 인코딩 설정 로그 아웃풋 변경 확인 jq 확인slow 동작되는 Pod IP로 느린 동작 Pod 확인
필요 시, Envoy 프록시의 로깅 수준 상향으로 더욱 자세한 로그 확인 가능
엔보이 게이트웨이의 로깅 수준 높이기 INCREASING THE LOGGING LEVEL FOR THE INGRESS GATEWAY
현재 로깅 수준 확인
# 로깅 수준 조회
docker exec -it myk8s-control-plane istioctl proxy-config log deploy/istio-ingressgateway -n istio-system
istio-ingressgateway-6bb8fb6549-hcdnc.istio-system:
active loggers:
admin: warning
alternate_protocols_cache: warning
aws: warning
assert: warning
backtrace: warning
cache_filter: warning
client: warning
config: warning
connection: warning # 커넥션 범위에서는 네트워크 계층과 관련된 정보를 기록.
...
http: warning # HTTP 범위에서는 HTTP 헤더, 경로 등 애플리케이션과 관련된 졍보를 기록.
...
router: warning # 라우팅 범위에서는 요청이 어느 클러스터로 라우팅되는지 같은 세부 사항을 기록.
...
현재 로깅 수준 확인
사용할 수 있는 로깅 수준: none, error, warning, info, debug
각 범위에 로깅 수준을 서로 다르게 지정할 수 있음
Envoy 가 만들어내는 로그의 관심 영역의 로깅 수준만 레벨 상향 가능.
connection: 4계층(전송) 관련 로그, TCP 연결 세부 정보
http: 7계층(애플리케이션) 관련 로그, HTTP 세부 정보
router: HTTP 요청 라우팅과 관련된 로그
pool: 연결 풀이 연결의 업스트림 호스트를 획득하거나 삭제하는 방법과 관련된 로그
connection , http , router , pool 로거의 수준을 debug 로 상향
# connection , http , router , pool 로거의 수준을 debug 로 상향
docker exec -it myk8s-control-plane istioctl proxy-config log deploy/istio-ingressgateway -n istio-system \
--level http:debug,router:debug,connection:debug,pool:debug
# 로그 확인
kubectl logs -n istio-system -l app=istio-ingressgateway -f
k logs -n istio-system -l app=istio-ingressgateway -f > istio-igw-log.txt # 편집기로 열어서 보기
...
응답이 느린 업스트림의 IP 주소가 액세스 로그에서 가져온 IP 주소와 일치함 - 오동작하는 인스턴스가 딱 하나라는 심증을 더욱 굳힘
로그 [C17947] client disconnected 에 표시된 대로 클라이언트(프록시)는 업스트림 커넥션을 종료함 - 업스트림 인스턴스가 제한 시간 설정을 초과해 클라이언트(프록시)가 요청을 종료한다는 예상과 일치함
ksniff (or tcpdump)로 네트워크 트래픽 검사 Inspect network traffic with ksniff
Pod 및 서비스 정보 확인 Flow 예시
# slow 파드 정보 확인
CATALOG_POD=$(kubectl get pods -l version=v2 -n istioinaction -o jsonpath={.items..metadata.name} | cut -d ' ' -f1)
kubectl get pod -n istioinaction $CATALOG_POD -owide
# catalog 서비스 정보 확인
kubectl get svc,ep -n istioinaction
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/catalog ClusterIP 10.200.1.178 <none> 80/TCP 10h
NAME ENDPOINTS AGE
endpoints/catalog 10.10.0.12:3000,10.10.0.13:3000,10.10.0.14:3000 10h
# istio-proxy 에서 기본 정보 확인 (tcpdump 는 생략 - sniff 로 캡처함.)
kubectl exec -it -n istioinaction $CATALOG_POD -c istio-proxy -- sudo whoami
kubectl exec -it -n istioinaction $CATALOG_POD -c istio-proxy -- ip -c addr
kubectl exec -it -n istioinaction $CATALOG_POD -c istio-proxy -- ip add show dev eth0
kubectl exec -it -n istioinaction $CATALOG_POD -c istio-proxy -- ip add show dev lo
slow pod 및 catalog 서비스 기본 정보 확인istio-proxy 기본 정보 확인
# https://askubuntu.com/questions/748941/im-not-able-to-use-wireshark-couldnt-run-usr-bin-dumpcap-in-child-process
# wsl2에서 권한 오류 해결 방안
## wireshark "couldn't run /usr/bin/dumpcap in child process" [duplicate]
# dumpcap 에 others 실행 권한 추가!!
sudo dpkg-reconfigure wireshark-common
sudo chmod +x /usr/bin/dumpcap
# → root 없이도 실행 및 캡처 가능
# sniff로 Pod dump 캡처 (lo)
kubectl sniff -n istioinaction $CATALOG_POD -i lo
# 실행되지 않을 경우 -p 옵션 (previledge) 옵션 추가 필요!
# istio-proxy 에 eth0 에서 패킷 덤프
kubectl sniff -n istioinaction $CATALOG_POD -c istio-proxy -i eth0 tcp port 3000
# istio-proxy 에 lo 에서 패킷 덤프
kubectl sniff -n istioinaction $CATALOG_POD -c istio-proxy -i lo
# istio-proxy 에 tcp port 3000 에서 패킷 덤프
kubectl sniff -n istioinaction $CATALOG_POD -c istio-proxy -i any tcp port 3000
sniff 로 패킷 캡처 - catalog pod (lo)
Wireshark 에서 TLS 암호 통신 확인 : istio-ingressgateway → [ (캡처 지점)istio-proxy ⇒ catalog application ]
Client Hello (SNI 확인) : EDS 의 클러스터 이름으로 접속 outbound_.80_.version-v2_.catalog.istioinaction.svc.cluster.localSNI 내 서버 이름 값이 EDS의 클러스터 이름인 이유: https 통신 시 EDS 기준 요청에 대한 통제를 하기 위한 것으로 보인다. 암호화된 내용 확인 : Encrypted Application Data 에 값 확인
Wireshark 에서 평문 통신 확인 : istio-ingressgateway→ [ istio-proxy(캡처 지점) ⇒catalog application ] istio-proxy 가 HTTPS를 복호화해서 평문으로 애플리케이션으로 요청 : x-envoy, x-b3 등 헤더 추가 확인
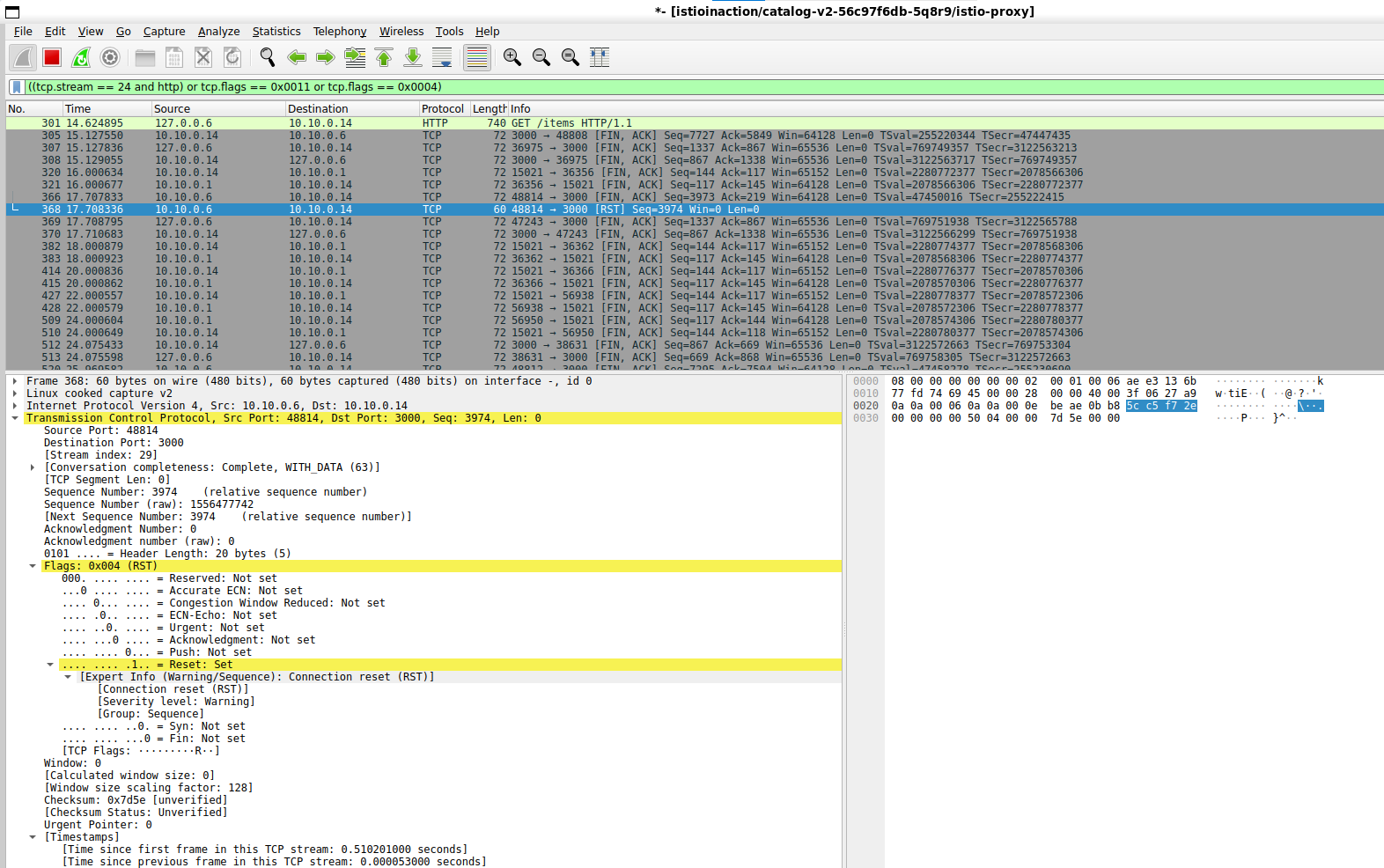
GET /items 패킷에서 우클릭 후 Follow → TCP Stream 클릭해서 해당 스트림(TCP) 필터링 tcp.stream eq 24 and http 로 필터링
Statistics → Flow Graph 확인 : 정상적으로 GET 요청과 200 응답 확인 tcp.stream eq 24 and http 로 필터링 tcp.stream eq 24으로 확인 (tcp+http)
필터 (tcp.stream == 24 and http) 사용 함. (숫자 - 24 은 각자 스트림 필터링 값 입력 필요)
istio-proxy 가 timeout 으로 먼저 종료된 것 확인 (catalog v2의 늦은 응답)Flow 예시
필터 ((tcp.stream == 24 and http) or tcp.flags == 0x0011 or tcp.flags == 0x0004) : TCP RST, FIN/ACK 플래그 필터링 추가 TCP RST로 연결 종료 확인
No. 301번에서 요청 후 0.5초 이상 응답이 없으니 (366번)368번에 istio-ingressgateway istio-proxy 가 TCP RST 로 연결 종료
즉, 현재 구성 상 istio-ingressgw → catalog 이므로, istio-ingressgw 가 TCP Timeout 후 종료 처리한 것을 알 수 있음
이후 369번은 catalog v2 istio-proxy 가 FIN/ACK를 applcation 에게 전달 이후 연결 종료
TCP control flags - 커넥션의 특정 상태 표시
Synchronization (SYN): 커넥션을 새로 수립하는 데 사용
Acknowledgment (ACK): 패킷 수신이 성공했음을 확인하는 데 사용
Finish (FIN): 커넥션 종료를 요청하는 데 사용
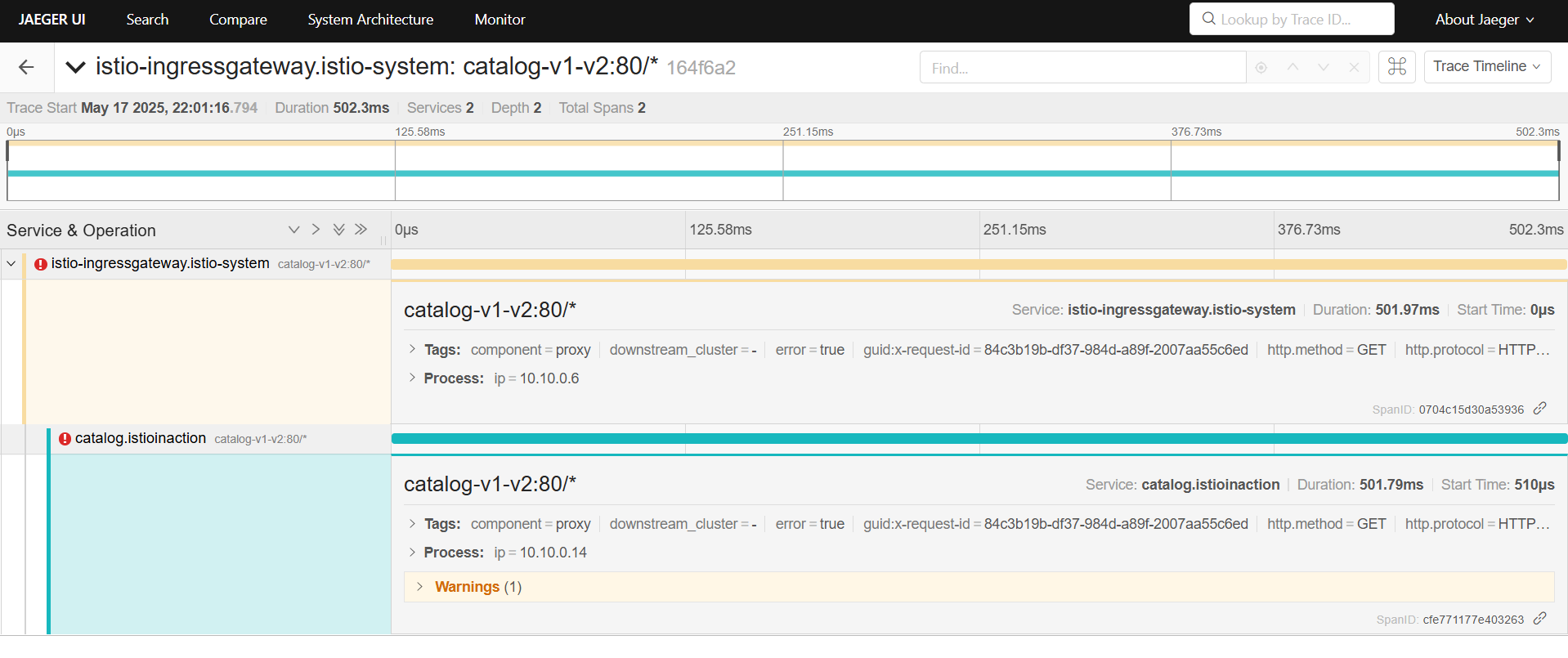
kiali 확인
jaeger ui
네트워크 트래픽 검사로 클라이언트가 커넥션 종료를 시작했으며, 서버에서 요청 응답이 느렸음을 확인.
10.4 Envoy 텔레메트리로 자신의 애플리케이션 이해하기
Grafana에서 실패한 요청 비율 찾기 Finding the rate of failing requests in Grafana
Grafana - Istio Service 대시보드 ⇒ Service(catalog.istioinaction..) , Reporter(source) 선택
클라이언트 성공률은 요청 중 70% 정도(스샷은 79%)로 30% 정도 실패. ⇒ Client 응답에 5xx가 30% 정도 있음 상태 코드 504 (’Gateway timeout’)로 표기되어 클라이언트 측 실패율에 반영
서버 성공률은 100%, 즉 서버 문제는 아님 ⇒ Server 응답에는 5xx 없음. Envoy 프록시가 다운스트림 종료 요청에 대한 응답 코드를 0으로 표시하며, 이는 5xx 응답이 아니라서 실패율에 포함되지 않음
[Ingress Gateway : 응답 플래그 UT, 상태 코드 504] ⇒ (요청 타임아웃) ⇒ [catalog v2 : 응답 플래그 DC, 상태 코드 0]클라이언트와 서버가 설정한 응답 플래그와 응답 코드의 차이점
올바른 값은 클라이언트가 보고하는 성공률
실패율이 2-30%이므로 빠른 확인 필요
다만, Grafana 대시보드는 단지 catalog 서비스에 속한 모든 워크로드(v1,v2) 성공률만 확인 가능하였음
이슈 있는 단일 인스턴스 식별을 위해 좀 더 상세한 출력이 필요
프로메테우스를 사용해 영향받는 파드 쿼리하기 Querying the affected Pods using Prometheus
그라파나 대시보드 정보 부족으로 프로메테우스에 직접 쿼리
ex) Pod 별 실패율에 대한 메트릭 쿼리
destination 이 보고한 요청
destination 서비스가 catalog인 요청
응답 플래그가 DC(다운스트림 커넥션 종료)인 요청 ⇒ 서버 입장에서는 응답을 하려는데, 클라이언트가 먼저 끊어 버린 것!
sort_desc( # 가장 높은 값부터 내림차순 정렬
sum( # irate 값들을 집계
irate( # 요청 수 초당 증가율
istio_requests_total {
reporter="destination", # 서버(destination) 측에서 보고한 메트릭만 필터링
destination_service=~"catalog.istioinaction.svc.cluster.local", # catalog 가 서버(destination)측인 메트릭만 필터링
response_flags="DC" # DC (다운스트림 커넥션 종료)로 끝난 메트릭만 필터링
}[5m]
)
)by(response_code, pod, version) # 응답 코드(response_code), 대상 pod, 버전(version) 별로 분리 => sum.. 합산
)
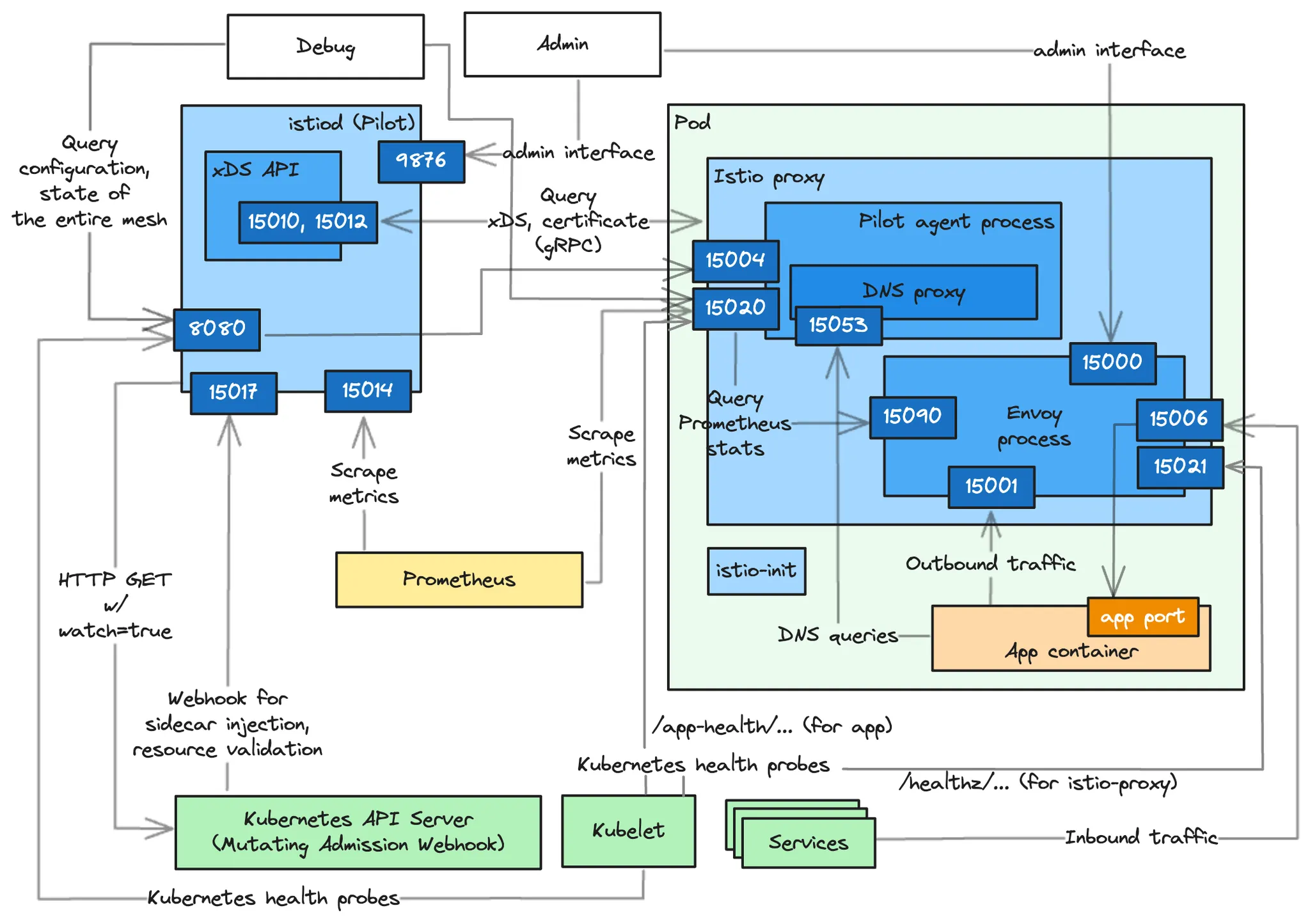
15010 : xDS API 및 인증서 발급을 평문으로 노출한다. 트래픽을 스니핑할 수 있으므로 이 포트는 사용하지 않는 것이 좋다.
15012 : 15010 포트와 노출하는 정보는 같지만 보안을 적용한다. 이 포트는 TLS를 사용해 ID를 발급하여, 후속 요청은 상호 인증된다.
15014 : 11장에서 다룬 것과 같은 컨트롤 플레인 메트릭을 노출한다.
15017 : 쿠버네티스 API 서버가 호출하는 웹훅 서버를 노출한다.
쿠버네티스 API 서버는 새로 만들어진 파드에 사이드카를 주입하고, Gateway나 VirtualServie 같은 이스티오 리소스를 검증하기 위해 호출한다.
디버깅 및 검사 포트
8080 : 이스티오 파일럿 디버그 엔드포인트를 노출한다.
9876 : istiod 프로세스에 대한 검사 정보를 노출한다.
2.1 Istio 파일럿 디버그 엔드포인트 The Istio Pilot debug endpoints
Istio 파일럿 디버그 엔드포인트는 파일럿이 알고 있는 전체 서비스 메시의 설정과 상태를 노출한다.
엔드포인트는 다음과 같은 질문들에 답한다.
프록시는 동기화됐는가? Are the proxies synchronized?
프록시에 대한 마지막 푸시는 언제 수행됐는가? When was the last push to a proxy performed?
xDS API의 상태는 어떤가? What’s the state of the xDS APIs?
디버그 엔드포인트로 접근
#
kubectl -n istio-system port-forward deploy/istiod 8080
open http://localhost:8080/debug
# 파일럿이 알고 있는 서비스 메시 상태
## 클러스터, 루트, 리스너 설정
curl -s http://localhost:8080/debug/adsz | jq
## 이 파일럿이 관리하는 모든 프록시에 대한 푸시를 트리거한다.
curl -s http://localhost:8080/debug/adsz?push=true
Pushed to 4 servers
## /debug/edsz=proxyID=<pod>.<namespace> : 프록시가 알고 있는 엔드포인트들
curl -s http://localhost:8080/debug/edsz=proxyID=webapp.istioninaction
## /debug/authorizationz : 네임스페이스에 적용되는 인가 정책 목록
curl -s http://localhost:8080/debug/authorizationz | jq
# 파일럿이 알고 있는 데이터 플레인 설정을 나타내는 엔드포인트
## 이 파일럿 인스턴스에 연결된 모든 엔보이의 버전 상태 : 현재 비활성화되어 있음
curl -s http://localhost:8080/debug/config_distribution
Pilot Version tracking is disabled. It may be enabled by setting the PILOT_ENABLE_CONFIG_DISTRIBUTION_TRACKING environment variable to true
## 이스티오 파일럿의 현재 알려진 상태에 따라 엔보이 설정을 생성한다.
curl -s http://localhost:8080/debug/config_dump?=proxyID=webapp.istioninaction
## 이 파일럿이 관리하는 프록시들을 표시한다.
curl -s http://localhost:8080/debug/syncz | jq
...
{
"cluster_id": "Kubernetes",
"proxy": "webapp-7685bcb84-lwsvj.istioinaction",
"istio_version": "1.17.8",
"cluster_sent": "ff5e6b2c-e857-4e12-b17e-46ad968567f4",
"cluster_acked": "ff5e6b2c-e857-4e12-b17e-46ad968567f4",
"listener_sent": "7280c908-010d-4788-807f-7138e74fe72e",
"listener_acked": "7280c908-010d-4788-807f-7138e74fe72e",
"route_sent": "2a1916c3-9c05-4ce5-8cfa-d777105b9205",
"route_acked": "2a1916c3-9c05-4ce5-8cfa-d777105b9205",
"endpoint_sent": "dffacd32-2674-4e39-8e76-17016ff32514",
"endpoint_acked": "dffacd32-2674-4e39-8e76-17016ff32514"
},
...
디버그 엔드포인가 노출될 경우 오용될 수 있는 민감 정보가 포함돼 있음
운영 환경에서는 Istio를 설치할 때 환경 변수 ENABLE_DEBUG_ON_HTTP 를 false 로 설정해 디버그 엔드포인트 비활성화를 권장
이렇게 하면 해당 엔드포인트에 의존하는 도구가 제 역할을 할 수 없지만, 향후 릴리스에서는 이러한 엔드포인트가 xDS를 통해 안전하게 노출될 것
파일럿이 알고 있는 서비스 메시 상태를 나타내는 엔드포인트
/debug/adsz : 클러스터, 루트, 리스너 설정
/debug/adsz?push=true : 이 파일럿이 관리하는 모든 프록시에 대한 푸시를 트리거한다.
/debug/edsz=*proxyID*=*<pod>.<namespace>* : 프록시가 알고 있는 엔드포인트들
/debug/authorizationz : 네임스페이스에 적용되는 인가 정책 목록
파일럿이 알고 있는 데이터 플레인 설정을 나타내는 엔드포인트
/debug/config_distribution : 이 파일럿 인스턴스에 연결된 모든 엔보이의 버전 상태
/debug/config_dump?proxyID=<pod>.<namespace> : 이스티오 파일럿의 현재 알려진 상태에 따라 엔보이 설정을 생성한다.
/debug/syncz : 이 파일럿이 관리하는 프록시들을 표시한다.
또한 프록시로 보낸 최신 논스 nonce 와 응답받은 최신 논스도 보여준다. 이 둘이 동일하면 프록시의 설정이 최신인 것이다.
2.2 ControlZ 인터페이스
Istio 파일럿에는 파일럿 프로세스의 현재 상태와 몇 가지 사소한 설정 가능성을 확인 할 수 있는 관리자 인터페이스가 함께 제공됨
이 인터페이스는 아래 표 D.1 에서 다룬 것 처럼 파일럿 인스턴스와 관련된 정보를 빠르게 조회할 수 있다.페이지 설명
페이지
설명
로깅 범위 Logging Scopes
이 프로세스에 대한 로깅은 범위별로 구성돼 있어 범위별로 로깅 단계를 별도로 설정할 수 있다.
메모리 사용량 Memory Usage
이 정보는 Go 런타임에서 수집되며 이 프로세스의 메모리 소비량을 나타낸다.
환경 변수 Environment Variables
이 프로세스에 정의된 환경 변수 집합이다.
프로세스 정보 Process Information
이 프로세스에 대한 정보다.
명령줄 인수 Command-Line Arguments
이 프로세스를 시작할 때 사용한 명령줄 인수 집합이다.
버전 정보 Version Info
바이너리(예: 이스티오 파일럿 1.7.3)와 Go 런타임(go 1.14.7)에 대한 정보다.
메트릭 Metrics
파일럿에서 노출하는 메트릭을 가져오는 방법 중 하나다.
시그널 Signals
실행 중인 프로세스에 SUGUSR1 시그널을 보낼수 있다.
접속 확인
# ControlZ 인터페이스 포트포워딩
kubectl -n istio-system port-forward deploy/istiod 9876
open http://localhost:9876
11장 튜닝
배경 설명
컨트롤 플레인 성능에 영향을 미치는 요소 이해하기 Understanding the factors of control-plane performance
성능 모니터링 방법 알아보기 How to monitor performance
주요 성능 메트릭 알아보기 What are the key performance metrics
성능 최적화 방법 이해하기 Understanding how to optimize performance
들어가며 : 컨트롤 플레인 성능 최적화
데이터 플레인 문제 해결을 다룬 앞 장에서는 프록시 설정 및 동작 문제를 진단하는 데 사용할 수 있는 디버깅 도구를 상세 확인
서비스 프록시 설정을 이해하면 예상과 다를 때 문제를 해결에 용이
11장에서는 컨트롤 플레인 성능 최적화에 초점, 다음 사항을 확인
컨트롤 플레인이 어떻게 서비스 프록시를 설정하는지
서비스 프록시 설정 과정을 느리게 만드는 요인이 무엇인지
서비스 프록시 설정 과정을 어떻게 모니터링하는지
성능을 향상시키기 위해 조정할 수 있는 변수는 무엇인지
11.1 컨트롤 플레인의 주요 목표
들어가며 : 유령 워크로드와 대응 방안
컨트롤 플레인
서비스 메시의 두뇌
서비스 메시 운영자를 위해 API를 노출
컨트롤 플레인 API 사용 시
메시의 동작을 조작
각 워크로드 인스턴스에 함께 배포된 서비스 프록시를 설정
서비스 메시 운영자(즉, 우리)가 이 API에 요청을 하는 것이 메시의 동작과 설정에 영향을 미치는 유일한 방법은 아님
컨트롤 플레인은 런타임 환경의 세부적인 내용들을 추상화
어떤 서비스가 존재하는지(서비스 디스커버리)
어떤 서비스가 정상인지
오토스케일링 이벤트
컨트롤 플레인은 쿠버네티스의 이벤트를 수신하고, 원하는 새 상태를 반영하고자 설정을 업데이트
이 상태 조정 절차는 올바르게 동작하는 메시를 유지하기 위해 계속됨
시기적절하게 일어나는 것이 중요
컨트롤 플레인이 상태 조정 절차를 적시에 하지 못한다면, 그 때마다 예기치 못한 결과로 이어짐
워크로드는 이미 바뀐 상태로 설정돼 있기 때문
성능 저하될 때 발생하는 흔한 증상을 ‘유령 워크로드 phantom workload’ 라고 지칭
이미 사라진 엔드포인트로 트래픽을 라우팅하도록 서비스가 설정돼 있으므로 요청이 실패
유령 워크로드의 개념오래된 설정으로 트래픽을 '유령 워크로드' 로 라우팅
비정상이 된 워크로드가 이벤트를 트리거
업데이트가 지연되면 서비스가 낡은 설정을 지님
오래된? 설정 때문에 서비스가 트래픽이 존재하지 않은 워크로드로 라우팅
데이터 플레인의 궁극적 일관성eventually consistent 성질 덕분에 설정이 잠깐 낡은 것은 크 문제되지 않음 (다른 보호 기체를 사용할 수 있기 때문)
ex) 네트워크 문제로 요청이 실패하면 요청은 기본적으로 두 번 재시도되므로, 아마도 다른 정상 엔드포인트가 처리
또 다른 교정 방법: 이상값 감지
엔드포인트로 보낸 요청이 실패했을 때 클러스터에서 엔드포인트를 배제하는 것
그러나 지연이 몇 초를 넘어가면 최종 사용자에게 부정적인 영향을 미칠 수 있으므로 반드시 배제 필요
데이터 플레인 동기화 단계 이해하기 Understanding the steps of data-plane synchronization : 디바운스와 스로틀링
데이터 플레인을 원하는 상태로 동기화하는 과정 (여러 단계로 수행)
컨트롤 플레인은 쿠버네티스에서 이벤트를 수신
이벤트는 Envoy 설정으로 변환되어, 데이터 플레인의 서비스 프록시로 푸시
데이터 플레인 동기화 과정을 이해하면 컨트롤 플레인 성능을 미세 조정하고 최적화할 때 이뤄지는 의사결정 시 도움을 받을 수 있음
들어오는 변경 사항에 맞춰 데이터 플레인을 동기화하는 단계최신 설정을 워크로드에 푸시하는 작업의 순서
들어오는 이벤트가 동기화 과정을 시작
istiod 의 DiscoveryServer 구성 요소가 이 이벤트들을 수신
성능을 향상시키기 위해, 푸시 대기열에 이벤트를 추가하는 작업을 일정 시간 미루고 그 동안의 후속 이벤트를 병합해 일괄 처리
이를 ‘디바운스 debounce 한다’고 지칭 - 디바운스는 시간을 잡아먹는 작업이 너무 자주 실행되지 않도록 도움
지연 시간이 만료되면, DiscoveryServer가 병합된 이벤트를 푸시 대기열에 추가
푸시 대기열은 처리 대기 중인 푸시 목록을 유지 관리
istiod 서버는 동시에 처리되는 푸시 요청 개수를 제한 throttle 함
throttle는 처리 중인 항목이 더 빨리 처리되도록 보장하고 CPU 시간이 작업 간 콘텍스트 스위칭에 낭비되는 것을 방지
처리된 항목은 Envoy 설정으로 변환돼 워크로드로 푸시됨
디바운스와 스로틀링은 성능을 향상시키기 위해 설정 가능한 것
디바운스(디바운싱debouncing)와 스로틀링throttling 이라는 두 가지 방법을 사용해 과부하되지 않도록 스스로를 보호하는 방법 확인
성능을 결정짓는 요소 Factors that determine performance : 변경 속도, 할당된 리소스, 업데이트할 워크로드 개수, 설정 크기
동기화 프로세스를 잘 이해하면 - 컨트롤 플레인의 성능에 영향을 미치는 요소를 자세히 설명할 수 있음컨트롤 플레인 성능에 영향을 주는 속성들
변경 속도 The rate of changes
변경 속도가 빠를수록 데이터 플레인을 동기화 상태로 유지하는 데 더 많은 처리가 필요
할당된 리소스 Allocated resources
수요가 istiod에 할당된 리소스를 넘어서면 작업을 대기열에 넣어야하므로 업데이트 배포가 느려짐
업데이트할 워크로드 개수 Number of workloads to update
더 많은 워크로드에 업데이트를 배포하려면 네트워크 대역폭과 처리 능력이 더 많이 필요
설정 크기 Configuration size
더 큰 엔보이 구성을 배포하려면 처리 능력과 네트워크 대역폭이 더 많이 필요
위 요소들에 부함한 성능 최적화 확인
성능 최적화를 위해 프로메테우스가 istiod에서 수집한 메트릭을 시각화한 그라파나 대시보드(8장에서 준비함)를 사용해 병목 지점을 판단해야 함
서비스가 어떻게 동작하는지에 대한 외부의 시각을 이해하기 위해 모니터링해야 하는 네 가지 주요 메트릭
특정 서비스가 자신의 서비스 수준 목표 SLO 에서 벗어난 경우, 네 가지 황금 신호 메트릭을 통해 원인을 분석하는 통찰력을 얻을 수 있음
네 가지 신호
지연 시간
포화도
오류
트래픽
컨트롤 플레인의 메트릭을 빠르게 살펴보려면 다음 명령어로 쿼리
# 실습 환경 준비
kubectl -n istioinaction apply -f services/catalog/kubernetes/catalog.yaml
kubectl -n istioinaction apply -f ch11/catalog-virtualservice.yaml
kubectl -n istioinaction apply -f ch11/catalog-gateway.yaml
# 확인
kubectl get deploy,gw,vs -n istioinaction
# 반복 설정 해두기
while true; do curl -s http://catalog.istioinaction.io:30000/items ; date "+%Y-%m-%d %H:%M:%S" ; sleep 1; echo; done
# 컨트롤 플레인 메트릭 확인
kubectl exec -it -n istio-system deploy/istiod -- curl localhost:15014/metrics
# HELP citadel_server_csr_count The number of CSRs received by Citadel server.
# TYPE citadel_server_csr_count counter
citadel_server_csr_count 3
...
실습 서비스 배포 확인서비스 반복 조회 - while 컨트롤 플레인 메트릭 확인
지연 시간: 데이터 플레인을 업데이트하는 데 필요한 시간LATENCY: THE TIME NEEDED TO UPDATE THE DATA PLANE
지연 시간 신호를 사용 시 알 수 있는 것
서비스가 어떻게 동작하는지를 서비스 외부의 최종 사용자 관점에서 확인 가능
지연 시간 증가가 의미하는 것
서비스의 성능이 저하된 것
성능 저하의 원인이 무엇인지는 알 수 없음 (원인을 알려면 다른 신호 조사 필요)
Istio 컨트롤 플레인에서 지연 시간 측정 방법
컨트롤 플레인이 데이터 플레인에 업데이트를 얼마나 빠르게 배포하는지로 측정
지연 시간을 측정하는 주요 메트릭
pilot_proxy_convergence_time
보조적으로 동기화 절차 중 대부분의 시간을 소비하는 단계의 이해를 돕는 보조 메트릭도 두 가지 존재
pilot_proxy_queue_time
pilot_xds_push_time
동기화 단계 중 지연 시간 측정 메트릭이 다루는 부분전체 지연 시간 중 각 메트릭이 다루는 부분들
pilot_proxy_convergence_time : 프록시 푸시 요청이 대기열에 안착한 순간부터 워크로드에 배포되기까지 전체 과정의 지속 시간을 측정
pilot_proxy_queue_time : 워커가 처리할 때까지 푸시 요청이 대기열에서 기다린 시간을 측정
푸시 대기열에서 상당한 시간이 걸리는 경우, istiod를 수직으로 확장해 동시 처리 능력을 높일 수 있음
pilot_xds_push_time : Envoy 설정을 워크로드로 푸시하는 데 필요한 시간을 측정
시간이 늘어나면, 전송되는 데이터양 때문에 네트워크 대역폭이 과부하된 것
설정 업데이트 크기와 워크로드별 변화 빈도를 줄임으로써 이 상황을 상당히 개선할 수 있음
pilot_proxy_convergence_time 은 그라파나 대시보드에서 시각화 가능 (Istio Control Plane 대시보드 - Proxy Push Time 참고)
그래프 확인 시 Push의 99.9%는 워크로드에 배포하는 데 걸리는 시간이 100ms미만 (이상적)
histogram_quantile(0.5, sum(rate(pilot_proxy_convergence_time_bucket[1m])) by (le))
histogram_quantile(0.9, sum(rate(pilot_proxy_convergence_time_bucket[1m])) by (le))
histogram_quantile(0.99, sum(rate(pilot_proxy_convergence_time_bucket[1m])) by (le))
histogram_quantile(0.999, sum(rate(pilot_proxy_convergence_time_bucket[1m])) by (le))
(참고) 프로메테우스 쿼리 :le (누적 카운트) “less than or equal”
pilot_proxy_convergence_time_bucket
# le="0.1": 0.1초 이하로 동기화 완료된 프록시가 10개
# le="1": 1초 이하로 완료된 프록시가 누적 20개
# le="+Inf": 모든 프록시 포함 → 누적 41개
...
pilot_proxy_convergence_time_bucket[1m]
rate(pilot_proxy_convergence_time_bucket[1m])
sum(rate(pilot_proxy_convergence_time_bucket[1m]))
sum(rate(pilot_proxy_convergence_time_bucket[1m])) by (le)
histogram_quantile(0.5, sum(rate(pilot_proxy_convergence_time_bucket[1m])) by (le))
histogram_quantile(0.9, sum(rate(pilot_proxy_convergence_time_bucket[1m])) by (le))
...
그라파나 대시보드에 2개의 패널(메트릭) 추가
대시보드 편집 및 패널 2개 추가하여 배치
Proxy Queue Time : PromQL - pilot_proxy_queue_time
histogram_quantile(0.5, sum(rate(pilot_proxy_queue_time_bucket[1m])) by (le))
histogram_quantile(0.9, sum(rate(pilot_proxy_queue_time_bucket[1m])) by (le))
histogram_quantile(0.99, sum(rate(pilot_proxy_queue_time_bucket[1m])) by (le))
histogram_quantile(0.999, sum(rate(pilot_proxy_queue_time_bucket[1m])) by (le))
XDS Push Time : PromQL - pilot_xds_push_time_bucket
histogram_quantile(0.5, sum(rate(pilot_xds_push_time_bucket[1m])) by (le))
histogram_quantile(0.9, sum(rate(pilot_xds_push_time_bucket[1m])) by (le))
histogram_quantile(0.99, sum(rate(pilot_xds_push_time_bucket[1m])) by (le))
histogram_quantile(0.999, sum(rate(pilot_xds_push_time_bucket[1m])) by (le))
패널 배치
메시에 워크로드를 추가하면 관련 메트릭에서 지연 시간 점진적 증가
약간의 증가는 당연하나, 지연 시간이 허용할 수 있는 임계값를 넘어가면 얼럿 트리거 필요
다음 기준으로 임계값 고려 권장
Warning 심각도 severity : 10초 이상 동안 지연 시간이 1초를 초과하는 경우
Critical 심각도 severity : 10초 이상 동안 지연 시간이 2초를 초과하는 경우
지연 시간이 늘어났다는 것은 컨트롤 플레인 성능이 저하됐음을 알리는 가장 좋은 지표이지만, 성능 저하 원인에 대한 정보는 확인 불가
저하 원인을 알아보려면 다른 메트릭 파악 필요
포화도: 컨트롤 플레인이 얼마나(CPU, MEM 리소스) 가득 차 있는가?SATURATION: HOW FULL IS THE CONTROL PLANE?
포화도 메트릭은 리소스 사용량을 나타냄
사용률이 90% 이상이면 서비스는 포화된 것이거나 곧 포화됨
istiod가 포화되면? 배포 업데이트가 느려짐
푸시 요청이 대기열에서 더 오래 처리를 기다리기 때문
포화는 보통 가장 제한적인 리소스 때문에 일어남
istiod는 CPU 집중적이므로, 보통은 CPU가 가장 먼저 포화됨
CPU 사용률 측정 패널 확인CPU 패널 확인
container_cpu_usage_seconds_total : 쿠버네티스 컨테이너가 보고하는 (istiod 파드) CPU 사용률을 측정 - Docs
# Cumulative cpu time consumed by the container in core-seconds
container_cpu_usage_seconds_total
container_cpu_usage_seconds_total{container="discovery"}
container_cpu_usage_seconds_total{container="discovery", pod=~"istiod-.*|istio-pilot-.*"}
sum(irate(container_cpu_usage_seconds_total{container="discovery", pod=~"istiod-.*|istio-pilot-.*"}[1m]))
컨트롤 플레인 동작을 최적화하기 위해 다른 접근법을 시도해 왔다가 포화에 이르렀다면, 리소스를 늘리는 것이 최선의 선택일 것
트래픽: 컨트롤 플레인의 부하는 어느 정도인가?TRAFFIC: WHAT IS THE LOAD ON THE CONTROL PLANE?
트래픽: 시스템이 겪는 부하를 측정
ex) 웹 애플리케이션에서 부하는 초당 요청 수 (rps) 로 정의
Istio 컨트롤 플레인의 트래픽 측정
수신 트래픽(설정 변경 형태)
송신 트래픽(데이터 플레인으로 변경 푸시)
성능을 제한하는 요인을 찾으려면 양방향 트래픽모두 측정 필요
측정치 기반하여 성능 개선 여러 방식 시도 가능Pilot Pushes - 푸시 빈도 / XDS Active Connections - 컨트롤 플레인이 관리하는 엔드포인트 개수.
수신 트래픽에 대한 메트릭
pilot_inbound_updates
각 istiod 인스턴스가 설정 변경을 수신한 횟수
pilot_push_triggers
푸시를 유발한 전체 이벤트 횟수
푸시 원인은 서비스, 엔드포인트, 설정 중 하나
여기서 설정이란 Gateway나 VirtualService 같은 istio 커스텀 리소스
pilot_services
파일럿이 인지하고 있는 서비스 개수를 측정
파일럿이 인지하는 서비스 개수가 늘어날수록, 이벤트를 수신할 때 Envoy 설정을 만들어내는 데 필요한 처리가 더 많아짐
따라서 istiod가 수신 트래픽 때문에 받는 부하량이 결정되는데 중요한 역할
avg(pilot_virt_services{app="istiod"}) # istio vs 개수: kubectl get vs -A --no-headers=true | wc -l avg(pilot_services{app="istiod"}) # k8s service 개수: kubectl get svc -A --no-headers=true | wc -l
발신 트래픽에 대한 메트릭 ㅇ
pilot_xds_pushes
리스너, 루트, 클러스터, 엔드포인트 업데이트와 같이 컨트롤 플레인이 수행하는 모든 유형의 푸시를 측정
avg(pilot_virt_services{app="istiod"}) # istio vs 개수: kubectl get vs -A --no-headers=true | wc -l
avg(pilot_services{app="istiod"}) # k8s service 개수: kubectl get svc -A --no-headers=true | wc -l
# docker exec -it myk8s-control-plane istioctl proxy-status
pilot_xds
pilot_xds{app="istiod"}
sum(pilot_xds{app="istiod"})
sum(pilot_xds{app="istiod"}) by (pod)
envoy_cluster_upstream_cx_tx_bytes_total
네트워크로 전송된 설정 크기를 측정
Istio Control Plane - XDS Requests Size 패널의 Legend: XDS Request Bytes Average 로 확인 가능
istiod 인스턴스 하나가 인그레스 및 이그레스 게이트웨이를 포함해 워크로드(istio-proxy 동작)를 13개 관리하며, 서비스는 총 600개(svc + vs + gw) 인지하도록 만듬
서비스 개수는 엔보이 설정을 만드는 데 필요한 처리량을 늘리고, 워크로드로 보내야 하는 설정을 부풀림
최적화 전 성능 측정하기 Measuring performance before optimizations Sidecar
들어가며: 테스트 실행
이제 테스트로 컨트롤 플레인 성능을 판단할 것
테스트는 서비스를 반복적으로 만들어 부하를 생성하고, 프록시에 설정을 업데이트하는 데 걸리는 지연 시간과 P99 값과 푸시 개수를 측정
P99 이해하기
P99(또는 percentile 백분위 99)는 업데이트 전파 중 가장 빠른 99%의 최대 지연 시간을 측정
ex) ‘P99 지연 시간이 80ms이다’는 요청 중 99%가 80ms 보다 빠르게 전파됐음을 의미
각 요청이 정확히 어떻게 분포하는지는 알지 못하며, 대부분은 수 ms 범위일 수 있음
그러나 가장 빠른 99%만을 고려할 때 가장 느린 요청도 80ms안에 처리됐음을 알 수 있음
(첫 번째) 테스트를 10회 반복하되, 반복 사이에 2.5초 간격 두기 (변경을 흩뿌려 배치 처리되는 상황을 피하려는 것)
bin/performance-test.sh : 파일 수정 해두기! $GATEWAY:30000/items
#!/bin/bash
main(){
## Pass input args for initialization
init_args "$@"
SLEEP_POD=$(kubectl -n istioinaction get pod -l app=sleep -o jsonpath={.items..metadata.name} -n istioinaction | cut -d ' ' -f 1)
PRE_PUSHES=$(kubectl exec -n istio-system deploy/istiod -- curl -s localhost:15014/metrics | grep pilot_xds_pushes | awk '{total += $2} END {print total}')
if [[ -z "$PRE_PUSHES" ]]; then
echo "Failed to query Pilot Pushes from prometheus."
echo "Have you installed prometheus as shown in chapter 7?"
exit 1
fi
echo "Pre Pushes: $PRE_PUSHES"
INDEX="0"
while [[ $INDEX -lt $REPS ]]; do
SERVICE_NAME="service-`openssl rand -hex 2`-$INDEX"
create_random_resource $SERVICE_NAME &
sleep $DELAY
INDEX=$[$INDEX+1]
done
## Wait until the last item is distributed
while [[ "$(curl --max-time .5 -s -o /dev/null -H "Host: $SERVICE_NAME.istioinaction.io" -w ''%{http_code}'' $GATEWAY:30000/items)" != "200" ]]; do
# curl --max-time .5 -s -o /dev/null -H "Host: $SERVICE_NAME.istioinaction.io" $GATEWAY/items
sleep .2
done
echo ==============
sleep 10
POST_PUSHES=$(kubectl exec -n istio-system deploy/istiod -- curl -s localhost:15014/metrics | grep pilot_xds_pushes | awk '{total += $2} END {print total}')
echo
LATENCY=$(kubectl -n istioinaction exec -it $SLEEP_POD -c sleep -- curl "$PROM_URL/api/v1/query" --data-urlencode "query=histogram_quantile(0.99, sum(rate(pilot_proxy_convergence_time_bucket[1m])) by (le))" | jq '.. |."value"? | select(. != null) | .[1]' -r)
echo "Push count:" `expr $POST_PUSHES - $PRE_PUSHES`
echo "Latency in the last minute: `printf "%.2f\n" $LATENCY` seconds"
}
create_random_resource() {
SERVICE_NAME=$1
cat <<EOF | kubectl apply -f -
---
kind: Gateway
apiVersion: networking.istio.io/v1alpha3
metadata:
name: $SERVICE_NAME
namespace: $NAMESPACE
spec:
servers:
- hosts:
- "$SERVICE_NAME.istioinaction.io"
port:
name: http
number: 80
protocol: HTTP
selector:
istio: ingressgateway
---
apiVersion: v1
kind: Service
metadata:
labels:
app: catalog
name: $SERVICE_NAME
namespace: $NAMESPACE
spec:
ports:
- name: http
port: 80
protocol: TCP
targetPort: 3000
selector:
app: catalog
---
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: $SERVICE_NAME
namespace: $NAMESPACE
spec:
hosts:
- "$SERVICE_NAME.istioinaction.io"
gateways:
- "$SERVICE_NAME"
http:
- route:
- destination:
host: $SERVICE_NAME.istioinaction.svc.cluster.local
port:
number: 80
---
EOF
}
help() {
cat <<EOF
Poor Man's Performance Test creates Services, Gateways and VirtualServices and measures Latency and Push Count needed to distribute the updates to the data plane.
--reps The number of services that will be created. E.g. --reps 20 creates services [0..19]. Default '20'
--delay The time to wait prior to proceeding with another repetition. Default '0'
--gateway URL of the ingress gateway. Defaults to 'localhost'
--namespace Namespace in which to create the resources. Default 'istioinaction'
--prom-url Prometheus URL to query metrics. Defaults to 'prom-kube-prometheus-stack-prometheus.prometheus:9090'
EOF
exit 1
}
init_args() {
while [[ $# -gt 0 ]]; do
case ${1} in
--reps)
REPS="$2"
shift
;;
--delay)
DELAY="$2"
shift
;;
--gateway)
GATEWAY="$2"
shift
;;
--namespace)
NAMESPACE="$2"
shift
;;
--prom-url)
PROM_URL="$2"
shift
;;
*)
help
;;
esac
shift
done
[ -z "${REPS}" ] && REPS="20"
[ -z "${DELAY}" ] && DELAY=0
[ -z "${GATEWAY}" ] && GATEWAY=localhost
[ -z "${NAMESPACE}" ] && NAMESPACE=istioinaction
[ -z "${PROM_URL}" ] && PROM_URL="prom-kube-prometheus-stack-prometheus.prometheus.svc.cluster.local:9090"
}
main "$@"
여러 개의 임의 서비스 리소스를 생성 → Istio의 xDS Push횟수 증가량 측정, Prometheus에서 프록시 구성 수렴 시간(latency) 확인 ⇒ 최종적으로 Push 성능과 latency를 평가
# (참고) 호출
curl -H "Host: catalog.istioinaction.io" localhost:30000/items
# 확인
kubectl get svc -n istioinaction --no-headers=true | wc -l
kubectl get gw -n istioinaction --no-headers=true | wc -l
kubectl get vs -n istioinaction --no-headers=true | wc -l
# :30000 포트 정보 추가해둘것!
cat bin/performance-test.sh
...
Poor Man's Performance Test creates Services, Gateways and VirtualServices and measures Latency and Push Count needed to distribute the updates to the data plane.
--reps The number of services that will be created. E.g. --reps 20 creates services [0..19]. Default '20'
--delay The time to wait prior to proceeding with another repetition. Default '0'
--gateway URL of the ingress gateway. Defaults to 'localhost'
--namespace Namespace in which to create the resources. Default 'istioinaction'
--prom-url Prometheus URL to query metrics. Defaults to 'prom-kube-prometheus-stack-prometheus.prometheus:9090'
...
# 성능 테스트 스크립트 실행!
./bin/performance-test.sh --reps 10 --delay 2.5 --prom-url prometheus.istio-system.svc.cluster.local:9090
Pre Pushes: 335
...
ateway.networking.istio.io/service-00a9-9 created
service/service-00a9-9 created
virtualservice.networking.istio.io/service-00a9-9 created
==============
Push count: 510 # 변경 사항을 적용하기 위한 푸시 함수
Latency in the last minute: 0.45 seconds # 마지막 1분 동안의 지연 시간
# 확인
kubectl get svc -n istioinaction --no-headers=true | wc -l
kubectl get gw -n istioinaction --no-headers=true | wc -l
kubectl get vs -n istioinaction --no-headers=true | wc -l
(두 번째) 딜레이 없이 실행
# 성능 테스트 스크립트 실행 : 딜레이 없이
./bin/performance-test.sh --reps 10 --prom-url prometheus.istio-system.svc.cluster.local:9090
Push count: 51
Latency in the last minute: 0.47 seconds
# 확인
kubectl get svc -n istioinaction --no-headers=true | wc -l
kubectl get gw -n istioinaction --no-headers=true | wc -l
kubectl get vs -n istioinaction --no-headers=true | wc -l
그라파나:
(세 번째) 딜레이 좀 더 늘려서 실행
# 성능 테스트 스크립트 실행 : 딜레이 5초로 늘려서 실행
./bin/performance-test.sh --reps 10 --delay 5 --prom-url prometheus.istio-system.svc.cluster.local:9090
Push count: 510
Latency in the last minute: 0.43 seconds
Push Coun: 510
테스트 정리
(첫 번째) 테스트에 따르면, 현재 설정으로는 479회의 푸시가 P99 지연 시간 4.84초로 수행
Push count: 479
Latency in the last minute: 4.84 seconds
(두 번째) 테스트에 따르면, 서비스 간의 간격을 없애면, 푸시 횟수와 지연 시간 모두 떨어지는 것을 볼 수 있음 - 이벤트가 배치처리되어 더 적은 작업량으로 처리되기 때문
Push count: 206
Latency in the last minute: 0.50 seconds
사이드카를 사용해 푸시 횟수 및 설정 크기 줄이기REDUCING CONFIGURATION SIZE AND NUMBER OF PUSHES USING SIDECARS
마이크로서비스 환경에서는 한 서비스가 다른 서비스에 의존하게 되는 경우가 잦지만, 한 서비스가 다른 모든 가용 서비스에 접근해야 하는 것도 드문 일 (아니면 적어도 이런 상황을 피하려고는 함)
Sidecar 리소스를 워크로드에 적용하면, 컨트롤 플레인은 egress 필드를 사용해 워크로드가 어떤 서비스들에 접근해야 하는지 판단
덕분에 컨트롤 플레인은 관련 있는 설정과 업데이트를 파악하고 해당 프록시로만 보낼 수 있음
그 결과, 다른 모든 서비스에 도달하는 방법에 대한 설정을 모두 생성하고 배포하는 일을 방지해 ‘CPU, 메모리, 네트워크 대역폭 소모’를 줄일 수 있음
메시 범위 사이드카 설정으로 더 나은 기본값 정의하기 DEFINING BETTER DEFAULTS WITH A MESH-WIDE SIDECAR CONFIGURATIO그림 출처 https://netpple.github.io/docs/istio-in-action/Istio-ch11-performance
모든 서비스 프록시로 전송되는 엔보이 설정을 줄여 컨트롤 플레인 성능을 개선할 수 있는 가장 쉬운 방법
트래픽 송신을 istio-system 네임스페이스의 서비스로만 허용하는 사이드카 설정을 메시 범위로 정의하는 것
기본값을 이렇게 정의하면, 최소 설정으로 메시 내 모든 프록시가 컨트롤 플레인에만 연결하도록 하고 다른 서비스로의 연결 설정은 모두 삭제 가능
이 방식은 서비스 소유자를 올바른 길로 유도
워크로드용 사이드카 정의를 좀 더 구체적으로 정의할 수 있음
서비스에 필요한 트래픽 송신을 모두 명시적으로 기술하게 함(강제 유도)으로써 워크로드가 프로세스에 필요한 관련 설정을 최소한으로 수신할 수 있게 함
다음 사이드카 정의를 사용하면 설정 가능
메시 내 모든 서비스 사이드카가 istio-system 네임스페이스에 있는 Istio 서비스로만 연결하도록 설정 (메트릭을 수집할 수 있드록 프로메테우스 네임스페이스도 연결)
컨트롤 플레인은 서비스 프록시가 istio-system / prometheus 네임스페이스의 서비스로 연결할 수 있는 최소한의 설정만 갖도록 업데이트됨
적용 시 catalog 워크로드의 엔보이 설정 크기는 현저히 줄어야 함
# cat ch11/sidecar-mesh-wide.yaml
apiVersion: networking.istio.io/v1beta1
kind: Sidecar
metadata:
name: default # istio-system 네임스페이스의 사이드카는 메시 전체에 적용된다.
namespace: istio-system # 위 설명 동일.
spec:
egress:
- hosts:
- "istio-system/*" # istio-system 네임스페이스의 워크로드만 트래픽 송신을 할 수 있게 설정한다.
- "prometheus/*" # 프로메테우스 네임스페이스도 트래픽 송신을 할 수 있게 설정한다.
outboundTrafficPolicy:
mode: REGISTRY_ONLY # 모드는 사이드카에 설정한 서비스로만 트래픽 송신을 허용한다
sample nginx 배포 및 catalog 에서 접근 시 접근됨istio-system, prometheus 네임스페이스만 egress 설정 허용 후: catalog에서 nginx 접근 불가 / envoy config 크기 464k로 감소
설정 크기가 2MB에서 464KB로 대폭 감소
이점은 그것뿐이 아님 - 이제부터 컨트롤 플레인은 푸시를 더 적게 할 것
성능 테스트로 확인
# 성능 테스트 스크립트 실행!
./bin/performance-test.sh --reps 10 --delay 2.5 --prom-url prometheus.istio-system.svc.cluster.local:9090
...
Push count: 88 # 변경 사항을 적용하기 위한 푸시 함수
Latency in the last minute: 0.10 seconds # 마지막 1분 동안의 지연 시간
# 확인
kubectl get svc -n istioinaction --no-headers=true | wc -l
kubectl get gw -n istioinaction --no-headers=true | wc -l
kubectl get vs -n istioinaction --no-headers=true | wc -l
Push count: 83 / Latency 0.95 로 감소
예상대로 푸시 횟수와 지연 시간 모두 감소
이 성능 향상은 메시 범위 Sidecar 리소스를 정의하는 것이 얼마나 중요한지 나타냄
메시의 운영 비용을 절감
성능을개선
플랫폼의 사용자(테넌트 tenant)들에게 워크로드에 송신 트래픽을 명시적으로 정의하는 좋은 습관을 심어줄 수 있음
기존 클러스터에서는 서비스 중단을 방지하기 위해 플랫폼의 사용자들과 신중히 협의해야 함
구체적으로는 그들이 좀 더 구체적인 Sidecar 리소스로 워크로드의 송신 트래픽을 먼저 정의하도록 해야 함
송신 트래픽 설정 후 메시 범위에 디폴트 사이드카 설정을 적용 가능
항상 스테이징 환경에서 변경 사항 테스트 필요
사이드카 설정 범위(scope)
mesh-wide 메시 범위 사이드카
메시 내 모든 워크로드에 적용돼 기본값을 정의할 수 있음
다른 규칙을 명시적으로 지정하지 않는 한 트래픽 송신을 제한하는 식
메시 범위 사이드카 설정을 만들려면, Istio를 설치한 네임스페이스(우리의 경우 istio-system)에 적용하면 됨
메시 범위 사이드카의 이름 컨벤션은 default
namespace-wide 네임스페이스 범위 사이드카
메시 범위보다 좀 더 구체적
메시 범위 설정을 덮어 씀
네임스페이스 범위 사이드카 설정을 만들려면, workloadSelector 필드를 정의하지 않고 원하는 네임스페이스에 적용해야 함
컨트롤 플레인이 이벤트를 받았을 때 푸시 대기열에 추가하는 행동을 100ms 디바운스한다는 것을 의미
이 기간 동안에 추가로 발생하는 이벤트는 앞서 발생한 이벤트에 통합돼 작업이 다시 디바운스
이 기간 동안 이벤트가 발생하지 않으면, 결과 배치가 푸시 대기열에 추가돼 처리할 준비가 됨
ex) 100ms (기본값) 이내에 새로운 이벤트가 없으면 queue에 추가하고, 있으면 merge 후 다시 100ms 동안 대기 + 단, 최대 PILOT_DEBOUNCE_MAX 이내에서 허용
PILOT_DEBOUNCE_MAX
이벤트 디바운스를 허용할 최대 간을 지정
이 시간이 지나면 현재 병합된 이벤트가 푸시 대기열에 추가됨
기본값은 10초
PILOT_ENABLE_EDS_DEBOUNCE
엔드포인트 업데이트가 디바운스 규칙을 준수할지, 우선권을 줘 푸시 대기열에 즉시 배치할지를 지정
기본값은 true
엔드포인트 업데이트도 디바운스된다는 의미
PILOT_PUSH_THROTTLE
istiod가 동시에 처리하는 푸시 요청 개수를 지정
기본값은 100개의 동시 푸시
CPU 사용률이 낮은 경우, 스로틀 값을 높여서 업데이트를 더 빠르게 할 수 있다.
배치 기간 환경 변수 사용 시의 일반적인 지침 general guidance
컨트롤 플레인이 포화 상태이고 수신 트래픽이 성능 병목을 야기하는 경우: 이벤트 배치 처리 증가시키기
업데이트 전파를 더 빠르게 하는 것이 목표일 때: 이벤트 배치 처리를 줄이고 동시에 푸시하는 개수를 증가시킴 (단, 이 방식은 컨트롤 플레인이 포화 상태가 아닐 때만 권장)
컨트롤 플레인이 포화 상태이고 송신 트래픽이 성능 병목인 경우: 동시에 푸시하는 개수를 감소시키기
컨트롤 플레인이 포화 상태가 아니거나, 스케일 업을 했고 빠른 업데이트를 원하는 경우: 동시에 푸시하는 개수를 증가시키기
배치 기간 늘리기 INCREASING THE BATCHING PERIOD
배치의 효과를 보여주기 위해 PILOT_DEBOUNCE_AFTER 값을 말도 안 되게 높은 값인 2.5초로 지정하기 (기본값은 100ms == 0.1초) - 운영에서는 이러한 설정은 적절하지 않음!!
# myk8s-control-plane 진입 후 설치 진행
docker exec -it myk8s-control-plane bash
-----------------------------------
# demo 프로파일 컨트롤 플레인 배포 시 적용
istioctl install --set profile=demo --set values.pilot.env.PILOT_DEBOUNCE_AFTER="2500ms" --set values.global.proxy.privileged=true --set meshConfig.accessLogEncoding=JSON -y
exit
-----------------------------------
#
kubectl get deploy/istiod -n istio-system -o yaml
...
- name: PILOT_DEBOUNCE_AFTER
value: 2500ms
...
# 성능 테스트 스크립트 실행!
./bin/performance-test.sh --reps 10 --delay 2.5 --prom-url prometheus.istio-system.svc.cluster.local:9090
Push count: 28 # 변경 사항을 적용하기 위한 푸시 함수
Latency in the last minute: 0.10 seconds # 마지막 1분 동안의 지연 시간
PILOT_DEBOUNCE_MAX 로 정의한 한계값을 넘지 않는 한 모든 이벤트는 병합돼 푸시 큐에 더해짐
덕분에 푸시 횟수가 현저히 줄어듬(28회)
엔보이 설정을 만들고 워크로드로 푸시하는 추가 작업을 모두 피해 CPU 사용률과 네트워크 대역폭 소모가 줄어듬
지연 시간 메트릭은 디바운스 기간을 고려하지 않는다!LATENCY METRICS DO NOT ACCOUNT FOR THE DEBOUNCE PERIOD!최신 설정을 워크로드에 푸시하는 작업의 순서
디바운스 기간을 늘린 후 지연 시간 메트릭에 푸시 배포가 10ms 걸린 것으로 나타났지만, 실제는 그렇지 않음
지연 시간 메트릭이 측정하는 기간은 푸시 요청이 푸시 대기열에 추가된 시점부터 시작됨
즉, 이벤트들이 디바운드되는 동안 업데이트는 전달되지 않음
따라서 업데이트를 푸시하는 시간은 늘어났지만, 이는 지연 시간 메트릭에서는 나타나지 않게 됨!
이렇게 이벤트를 너무 오래 디바운스해 지연 시간이 늘어나면 성능이 낮을 때와 마찬가지로 설정이 낡게(오래되게) 됨
따라서 배치 속성을 조정할 때는 한 번에 너무 크게 변경하는 것보다는 조금씩 변경하는 것이 좋음
데이터 플레인은 보통 늦은 엔드포인트 업데이트에 영향을 받음
환경 변수PILOT_ENABLE_EDS_DEBOUNCE를false로 설정 시 엔드포인트 업데이트가디바운스 기간을 건너뛰어지연되지 않음을 보장할 수 있음
컨트롤 플레인에 리소스 추가 할당하기 ALLOCATING ADDITIONAL RESOURCES TO THE CONTROL PLAN
Sidecar 리소스를 정의하고 discovery selectors를 사용하고 배치를 설정한 후 성능 향상시키기
컨트롤 플레인에 리소스를 더 할당하는 것이 유일한 방법
컨트롤 플레인에 리소스를 더 할당하는 방법
istiod 인스턴스를 추가해 스케일 아웃
모든 istiod 인스턴스에 리소스를 추가로 제공해 스케일 업
성능 병목 원인에 따라 스케일 인/아웃 여부 결정됨
송신 트래픽이 병목일 때는 스케일 아웃
istiod 인스턴스당 관리하는 워크로드가 많을 때만 일어남
스케일 아웃은 istiod 인스턴스가 관리하는 워크로드 개수를 감소시킴
수신 트래픽이 병목일 때는 스케일 업
Envoy 설정을 생성하는 데 리소스(Service, VS, DR 등)을 많이 처리할 때만 일어남
스케일 업하면 istiod 인스턴스에 처리 능력을 더 제공
복제본 2 스케일 아웃과 리소스 스케일 업
#
kubectl get pod -n istio-system -l app=istiod
kubectl describe pod -n istio-system -l app=istiod
...
Requests:
cpu: 10m
memory: 100Mi
...
kubectl resource-capacity -n istio-system -u -l app=istiod
NODE CPU REQUESTS CPU LIMITS CPU UTIL MEMORY REQUESTS MEMORY LIMITS MEMORY UTIL
myk8s-control-plane 10m (0%) 0m (0%) 8m (0%) 100Mi (0%) 0Mi (0%) 90Mi (0%)
# myk8s-control-plane 진입 후 설치 진행
docker exec -it myk8s-control-plane bash
-----------------------------------
# demo 프로파일 컨트롤 플레인 배포 시 적용
istioctl install --set profile=demo \
--set values.pilot.resources.requests.cpu=1000m \
--set values.pilot.resources.requests.memory=1Gi \
--set values.pilot.replicaCount=2 -y
exit
-----------------------------------
#
kubectl get pod -n istio-system -l app=istiod
NAME READY STATUS RESTARTS AGE
istiod-5485dd8c48-6ngdc 1/1 Running 0 11s
istiod-5485dd8c48-chjsz 1/1 Running 0 11s
kubectl resource-capacity -n istio-system -u -l app=istiod
NODE CPU REQUESTS CPU LIMITS CPU UTIL MEMORY REQUESTS MEMORY LIMITS MEMORY UTIL
myk8s-control-plane 2000m (25%) 0m (0%) 119m (1%) 2048Mi (17%) 0Mi (0%) 107Mi (0%)
kubectl describe pod -n istio-system -l app=istiod
...
Requests:
cpu: 1
memory: 1Gi
...
컨트롤 플레인 성능 최적화의 요점
항상 워크로드에 사이드카 설정을 정의해야 함 - 이것만으로도 대부분의 이점을 얻을 수 있음
Istio 도입시 겪었던 Error : holdApplicationUntilProxyStarts: true - Blog
Pod 시작시 Network Error ⇒holdApplicationUntilProxyStarts: true설정 - Docs
Pod 종료시 Network Error ⇒terminationDrainDuration설정 혹은EXIT_ON_ZERO_ACTIVE_CONNECTIONS설정
terminationDrainDuration
he amount of time allowed for connections to complete on proxy shutdown. On receiving SIGTERM or SIGINT, istio-agent tells the active Envoy to start gracefully draining, discouraging any new connections and allowing existing connections to complete. It then sleeps for the terminationDrainDuration and then kills any remaining active Envoy processes. If not set, a default of 5s will be applied.
EXIT_ON_ZERO_ACTIVE_CONNECTIONS
When set to true, terminates proxy when number of active connections become zero during draining
Pod가 종료될 때 커넥션이 비정상적으로 종료되는 경우 : EXIT_ON_ZERO_ACTIVE_CONNECTIONS - Blog
Istio를 통한 header기반 API 라우팅/호출 시 cors preflight request 이슈 트러블슈팅 : http.corsPolicy - Blog
Istio xDS로 인한 connection 끊김 이슈 : excludeEgressPorts - Blog